
Una página no indexables es cuando de forma proactiva le indicamos a los buscadores que no queremos indexar nuestro contenido en los resultados de busuqeda
Con el objetivo de facilitar la priorización de indexación sobre nuestros contenidos de negocio.
La forma que podemos hacer esto es mediante las siguientes meta etiquetas.
Meta Etiqueta Noindex
Puedes implementar noindex de dos formas:
- Como etiqueta meta
- Como encabezado de respuesta HTTP.
Ambos métodos tienen el mismo efecto, así que elige el que mejor se adapte a tu sitio y a tu tipo de contenido.

Etiqueta <meta>
Para impedir que los rastreadores web de la mayoría de los buscadores indexen una página de tu sitio, coloca la siguiente meta etiqueta en la sección de la página:
<meta name="robots" content="noindex">
Si solo quieres impedir que lo hagan los rastreadores web de Google, incluye esta otra etiqueta meta:
<meta name="googlebot" content="noindex">
Encabezado de respuesta HTTP
En vez de usar una etiqueta meta, puedes devolver un encabezado X-Robots-Tag con los valores noindex o none en tu respuesta. Un encabezado de respuesta puede usarse en recursos que no sean HTML (como archivos PDF, de vídeo y de imagen). A continuación se muestra un ejemplo de una respuesta HTTP que incluye un encabezado X-Robots-Tag que indica a los rastreadores que no indexen una página:
HTTP/1.1 200 OK (…) X-Robots-Tag: noindex (…)
Documentación oficial de Google
Canonical
Una URL canónica es la URL de la página que Google considera más representativa de un conjunto de páginas duplicadas de tu sitio.
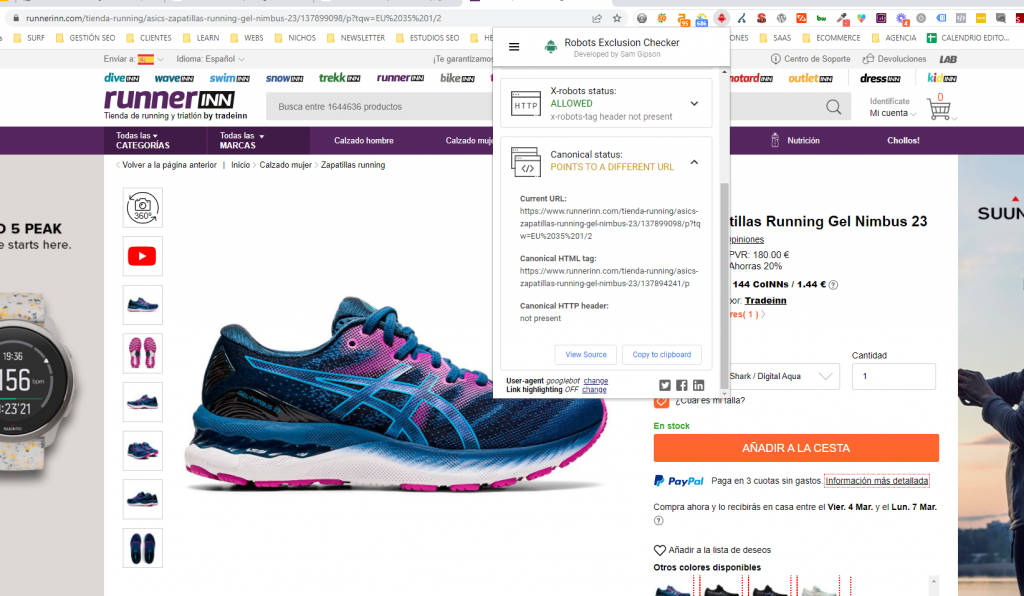
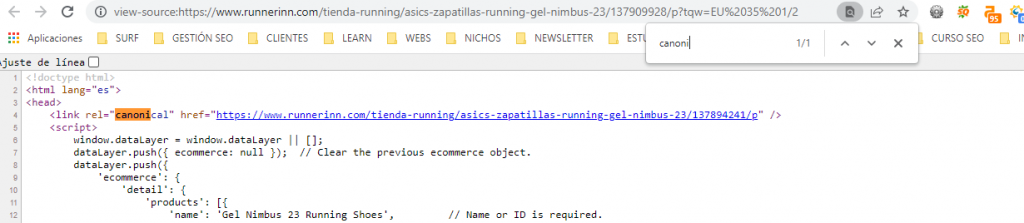
Documentación oficial de Google
Paginación
Son listados de páginas relacionadas entre si que agrupan un listado de items, cómo pueden ser productos o artículos de blogs.
Trabajar de forma eficiente la paginación podremos evitar la indexación de otras páginas del site
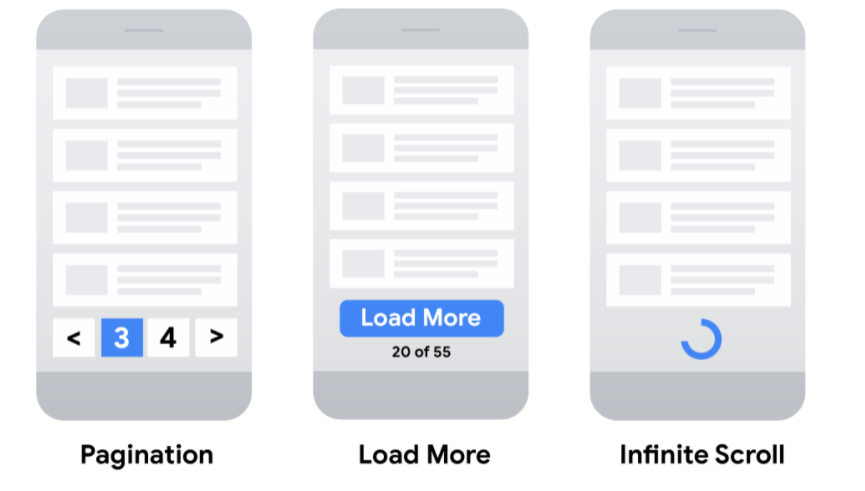
Documentación oficial de Google
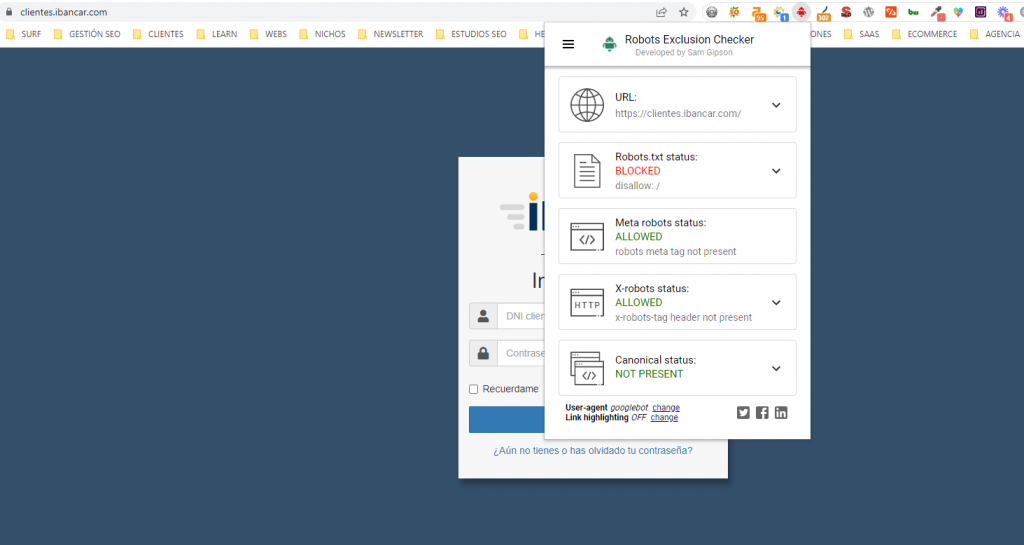
Problemática con el Robots.txt
Resaltar que el hecho de bloquear por robots.txt no significa que esta URL sea desindexada por Google.
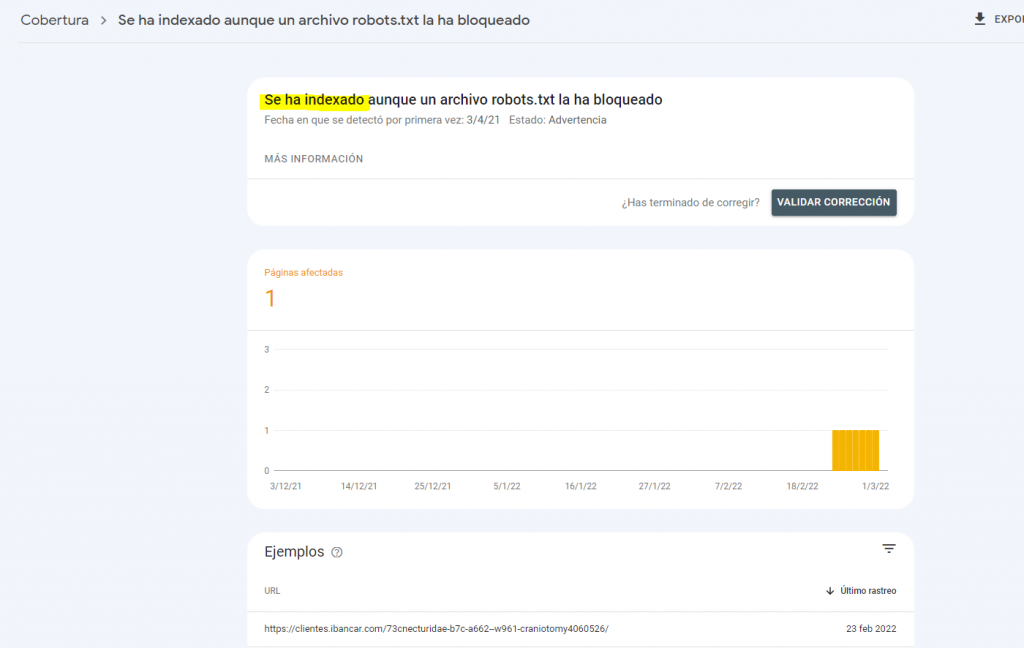
Ya que la URLs sigue con la etiqueta index y googlebot es la ultima información que tiene desde que la rastreó
Pagina no indexada por Google no por el usuario
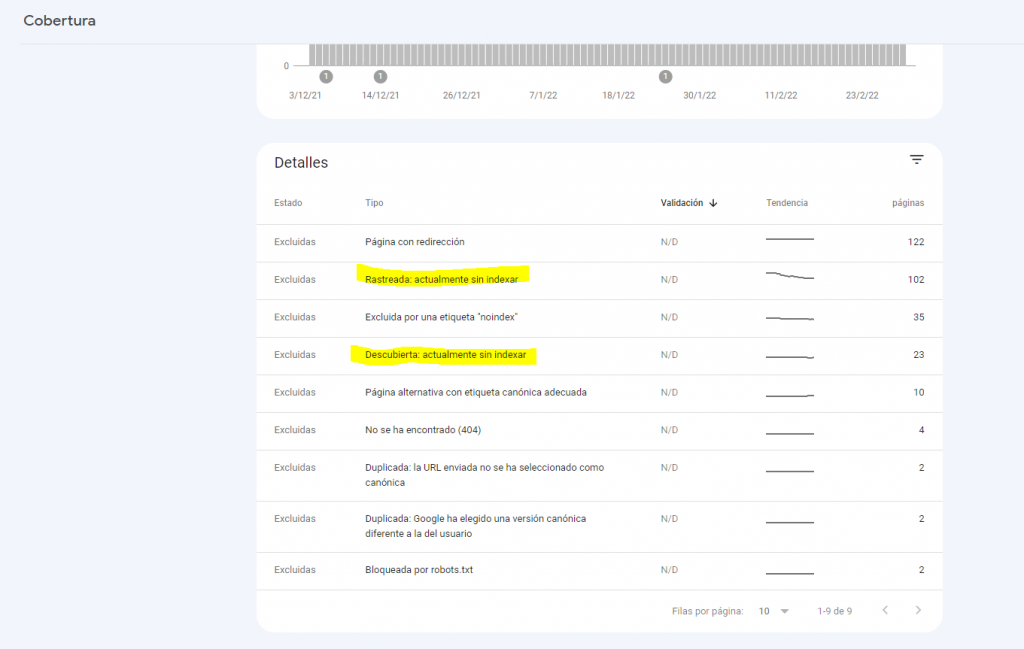
Esto sucede cuando Google ha decidido no indexar el contenido por si mismo. Este tipo de avisos los detectaremos gracias a Google Search Console en el apartado de cobertura:
Los hechos más comunes son:
- Descubierta: actualmente sin indexar
- Rastreada: actualmente sin indexar
- Duplicada: el usuario no ha indicado ninguna versión canónica
- Duplicada: Google ha elegido una versión canónica diferente a la del usuario
- Soft 404 (Thin Content)
Documentación oficial de Google
Si tienes alguna duda sobre la indexación de una web, no dudes en preguntarme ;D
