
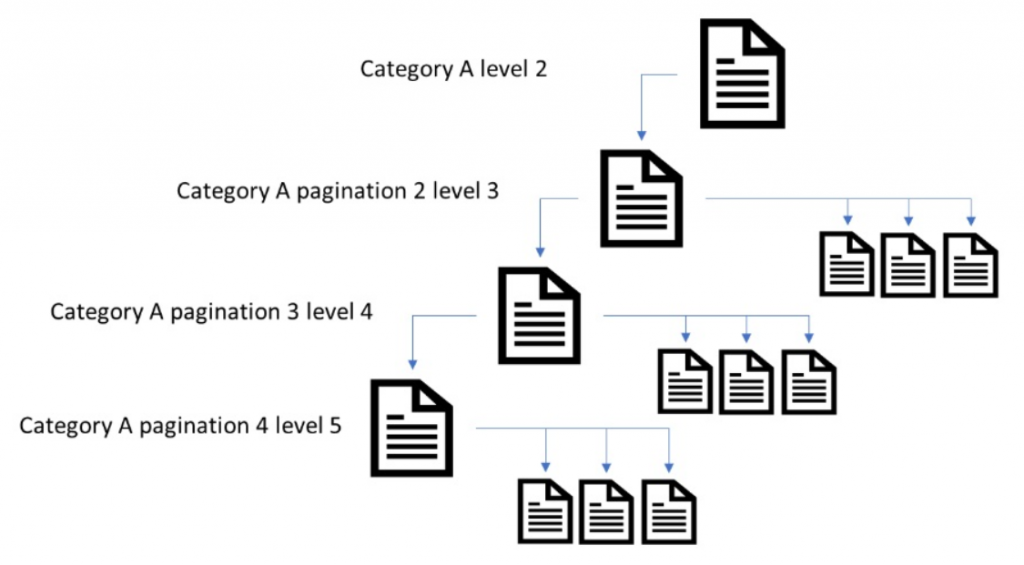
La paginación SEO del sitio es fundamental para la correcta indexación de este y la gestión del presupuesto de rastreo u Crawl budget.
Se utiliza en contextos que van desde la visualización de elementos en páginas de categorías, archivos de artículos, presentaciones de diapositivas de galerías y subprocesos de foros.
Para los profesionales de SEO, no se trata de si tendrá que lidiar con la paginación, sino de cuándo.
En cierto punto de crecimiento, los sitios web necesitan dividir el contenido en una serie de páginas componentes para la experiencia del usuario (UX).
Nuestro trabajo es ayudar a los motores de búsqueda a rastrear y comprender la relación entre estas URL para que indexen la página más relevante.
Con el tiempo, las mejores prácticas SEO de gestión de paginación han evolucionado. En el camino, muchos mitos se han presentado como hechos. Pero ya no.
Este artículo sobre la paginación seo encontrará lo siguiente:
- Desacredite los mitos sobre cómo la paginación perjudica al SEO.
- Presentarte la forma óptima de gestionar la paginación.
- Revise métodos incomprendidos o deficientes en el manejo de la paginación.
- Investigue cómo rastrear el impacto KPI de la paginación.
- Cómo la paginación mal implementada puede dañar el SEO
Sin embargo, en la mayoría de los casos, esto se debe a una falta de gestión correcta de la paginación, más que a la existencia de la paginación en sí.
Veamos los supuestos males de la paginación y cómo superar los problemas de SEO que podría causar.
La paginación provoca contenido duplicado
Corrija si la paginación se ha implementado incorrectamente, como tener una página «Ver todo» y páginas paginadas sin un rel = canonical correcto o si ha creado una página = 1 además de su página raíz.
Incorrecto cuando tienes paginación amigable con SEO. Incluso si sus etiquetas H1 y meta son las mismas, el contenido real de la página difiere. Entonces no es duplicación.
La paginación crea Thin Content
Corrija si ha dividido un artículo o una galería de fotos en varias páginas (para generar ingresos publicitarios al aumentar las vistas de página), dejando muy poco contenido en cada página.
Incorrecto cuando pones los deseos del usuario de consumir fácilmente tu contenido por encima de los ingresos por anuncios publicitarios o páginas vistas infladas artificialmente. Ponga una cantidad de contenido amigable «300 palabras minimo» para UX en cada página.

La paginación diluye las señales de clasificación
Correcto. La paginación hace que la equidad de los enlaces internos y otras señales de clasificación, como los vínculos de retroceso y las redes sociales, se dividan en páginas.
Pero puede minimizarse mediante el uso de la paginación solo en los casos en que un enfoque de contenido de una sola página podría causar una mala experiencia del usuario (por ejemplo, páginas de categorías de comercio electrónico).
Y en tales páginas, agregue tantos elementos como sea posible, sin ralentizar la página a un nivel notable, para reducir el número de páginas paginadas.
La paginación utiliza el presupuesto de rastreo (Crawl Budget)
Corrija si permite que Google rastree páginas paginadas. Y hay algunos casos en los que desearía utilizar ese presupuesto.
Por ejemplo, para que el robot de Google viaje a través de URL paginadas para llegar a páginas de contenido más profundas.
A menudo es incorrecto cuando configura el manejo de parámetros de paginación de Google Search Console en «No rastrear» o establece un rechazo de robots.txt, en el caso de que desee conservar su presupuesto de rastreo para páginas más importantes.
Gestionar la paginación según las mejores prácticas de SEO
Utilice enlaces de anclaje rastreables paginación con rel =

Para que los motores de búsqueda rastreen eficientemente páginas paginadas, el sitio debe tener enlaces de anclaje con atributos href a estas URL paginadas.
Asegúrese de que su sitio use para enlaces internos a páginas paginadas. No cargue enlaces de anclaje paginados o atributo href a través de JavaScript.
Además, debe indicar la relación entre las URL de componentes en una serie paginada con los atributos rel = «next» y rel = «prev».
Sí, incluso después del infame Tweet de Google de que ya no usan estos atributos de enlace.
¡Conozca y haga lo mejor para * sus * usuarios! #springiscoming
A medida que evaluamos nuestras señales de indexación, decidimos retirar rel = prev / next.
Los estudios demuestran que a los usuarios les encanta el contenido de una sola página, apunte a eso cuando sea posible, pero la función de varias partes también está bien para la Búsqueda de Google.
🎯 Poco después, Ilya Grigorik aclaró que rel = «next» / «prev» aún puede ser valioso. 🎯
En respuesta a @jonoalderson @googlewmc
¿Todos los sitios de comercio electrónico deberían qué? ¿Tomar sus 1000 listados de productos y ponerlos en una página?
Sin mencionar que no creo que los estándares de accesibilidad de WCAG hayan cambiado.
no, usa paginación. déjame replantearlo … Googlebot es lo suficientemente inteligente para encontrar su próxima página mirando los enlaces en la página, no necesitamos una señal explícita de «anterior, siguiente». y sí, hay otras buenas razones por las que es posible que desee o necesite agregarlas aún.
Google no es el único motor de búsqueda en la ciudad. Aquí está la opinión de Bing sobre el tema.
Frédéric Dubut – @CoperniX
Estamos usando rel prev / next (como la mayoría de las marcas) como pistas para el descubrimiento de páginas y la comprensión de la estructura del sitio.
En este punto, no estamos fusionando páginas en el índice en función de estas y no estamos usando prev / next en el modelo de clasificación.
Complemente el rel = «next» / «prev» con un enlace autoreferenciado rel = «canonical». Entonces / category Page = 4 debería rel = «canonical» a / categori Page = 4.
Esto es apropiado ya que la paginación cambia el contenido de la página y también lo es la copia maestra de esa página.
Si la URL tiene parámetros adicionales, inclúyalos en los enlaces rel = «prev» / «next», pero no los incluya en el rel = «canonical».
Por ejemplo:
Hacerlo indicará una relación clara entre las páginas y evitará la posibilidad de contenido duplicado.
Errores comunes a evitar en la paginación:
Colocando los atributos del enlace en el contenido de . Solo son compatibles con los motores de búsqueda dentro de la sección de su HTML.
Agregar un enlace rel = «prev» a la primera página (también conocida como la página raíz) en la serie o un enlace rel = «next» a la última. Para todas las demás páginas de la cadena, ambos atributos de enlace deben estar presentes.
Tenga cuidado con la URL canónica de su página raíz. Las posibilidades están en? Page = 2, rel = prev debe enlazar a lo canónico, no a? Page = 1.
El código de una serie de cuatro páginas se verá así:
Una etiqueta de paginación en la página raíz, que apunta a la siguiente página en serie.
<link rel="next" href="https://www.example.com/category?page=2″><link rel="canonical" href="https://www.example.com/category">
Dos etiquetas de paginación en la página 2.
<link rel="prev" href="https://www.example.com/category"><link rel="next" href="https://www.example.com/category?page=3″><link rel="canonical" href="https://www.example.com/category?page=2">
Dos etiquetas de paginación en la página 3.
<link rel="prev" href="https://www.example.com/category?page=2″><link rel="next" href="https://www.example.com/category?page=4″><link rel="canonical" href="https://www.example.com/category?page=3">
Una etiqueta de paginación en la página 4, la última página de la serie paginada.
<link rel="prev" href="https://www.example.com/category?page=3"><link rel="canonical" href="https://www.example.com/category?page=4">
Modificar elementos paginados en páginas
John Mueller comentó: «No tratamos la paginación de manera diferente. Los tratamos como páginas normales «.
Es decir, las páginas paginadas no son reconocidas por Google como una serie de páginas consolidadas en una sola pieza de contenido como lo aconsejaron anteriormente. Cada página paginada es elegible para competir contra la página raíz para el ranking.
Para alentar a Google a que devuelva la página raíz en los SERPs y evite las advertencias de «Duplicar meta descripciones» o «Duplicar etiquetas de título» en Google Search Console, modifique fácilmente su código.
Si la página raíz tiene la fórmula:

Las páginas paginadas sucesivas podrían tener la fórmula:

Estos títulos de página URL paginados y meta descripción son deliberadamente subóptimos para disuadir a Google de mostrar estos resultados, en lugar de la página raíz.
Si incluso con tales modificaciones, las páginas paginadas se clasifican en los SERP, pruebe otras tácticas de SEO en la página tradicionales como:
- Optimice las etiquetas de la página paginada H1.
- Agregue texto útil en la página a la página raíz, pero no páginas paginadas.
- Agregue una imagen de categoría con un nombre de archivo optimizado y una etiqueta alt a la página raíz, pero no páginas paginadas.
No incluya páginas paginadas en mapas de sitio XML
Si bien las URL paginadas son técnicamente indexables, no son una prioridad de SEO para gastar el presupuesto de rastreo.
Como tal, no pertenecen a su mapa del sitio XML.
Gestionar parámetros de paginación en Google Search Console
Si tiene una opción, ejecute la paginación a través de un parámetro en lugar de una URL estática. Por ejemplo:
example.com/category?page=2 sobre example.com/category/page-2
Si bien no hay ninguna ventaja al usar uno sobre el otro para fines de clasificación o rastreo, la investigación ha demostrado que Googlebot parece adivinar los patrones de URL basados en URL dinámicas. Por lo tanto, aumenta la probabilidad de un descubrimiento rápido.
En el lado negativo, puede causar trampas de rastreo si el sitio presenta páginas vacías para conjeturas que no son parte de la paginación actual
Por ejemplo, digamos que una serie contiene cuatro páginas.
Las URL con contenido se detienen en www.example.com/category?page=4
Si Google adivina www.example.com/category?page=7 y se carga una página en vivo, pero vacía, el bot desperdicia el presupuesto de rastreo y posiblemente se pierda en un número infinito de páginas.
Asegúrese de que se envíe un código de estado HTTP 404 para cualquier página paginada que no forme parte de la serie actual.
Otra ventaja del enfoque de parámetros es la capacidad de configurar el parámetro en Google Search Console para «Paginar» y, en cualquier momento, cambiar la señal a Google para que rastree «Todas las URL» o «Sin URL», según cómo desee utilizar su Presupuesto de rastreo. No se necesita desarrollador!
Nunca asigne contenido de página paginado a identificadores de fragmentos (#) ya que no se puede rastrear ni indexar, y como tal no es compatible con los motores de búsqueda.
Soluciones SEO mal entendidas, desactualizadas o completamente incorrectas para contenido paginado
Hacer nada

Google cree que Googlebot es lo suficientemente inteligente como para encontrar la siguiente página a través de enlaces, por lo que no necesita ninguna señal explícita.
El mensaje para SEO es esencialmente manejar la paginación sin hacer nada.
Si bien hay un núcleo de verdad en esta afirmación, al no hacer nada, está jugando con su SEO.
Muchos sitios han visto a Google seleccionar una página paginada para clasificar sobre la página raíz para una consulta de búsqueda.
Siempre tiene valor dar una guía clara a los rastreadores sobre cómo desea que indexen y muestren su contenido.
Canonicalizar a una página Ver todo
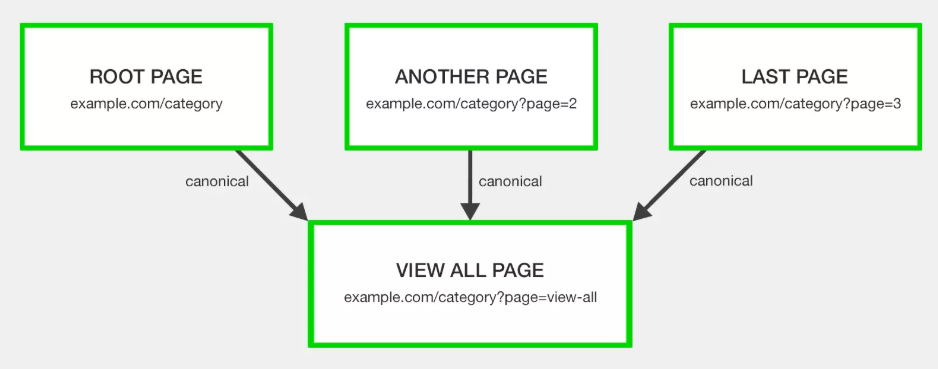
La página Ver todo fue ideada para contener todo el contenido de la página componente en una sola URL.
Con todas las páginas paginadas que tienen un rel = «canónico» a la página Ver todo para consolidar las señales de clasificación.
El argumento aquí es que los buscadores prefieren ver un artículo completo o una lista de elementos de categorías en una sola página, siempre que se cargue rápidamente y sea fácil de navegar.
El concepto era que si su serie paginada tiene una versión alternativa «Ver todo» que ofrece la mejor experiencia de usuario, los motores de búsqueda favorecerán esta página para su inclusión en los resultados de búsqueda en lugar de una página de segmento relevante de la cadena de paginación.
Lo que plantea la pregunta: ¿por qué tiene páginas paginadas en primer lugar?
Hagamos esto simple.
Si puede proporcionar su contenido en una sola URL mientras ofrece una buena experiencia de usuario, no hay necesidad de paginación o una versión Ver todo.
Si no puede, por ejemplo, una página de categoría con miles de productos sería ridículamente grande y tardaría demasiado en cargarse, luego paginar.
Ver todo no es la mejor opción, ya que no ofrecería una buena experiencia de usuario.
El uso de rel = «next» / «prev» y una versión Ver todo no da un mandato claro a los motores de búsqueda y generará rastreadores confusos.
No lo hagas
Canonicalizar a la primera página

Un error común es señalar el rel = «canónico» de todos los resultados paginados a la página raíz de la serie.
Algunas personas de SEO mal informadas sugieren esto como una forma de consolidar la autoridad en todo el conjunto de páginas a la página raíz, pero esto está mal informado.
La canonización incorrecta de la página raíz corre el riesgo de desviar a los motores de búsqueda para que piensen que solo tiene una página de resultados.
Googlebot no indexará las páginas que aparecen más adelante en la cadena ni reconocerá las señales del contenido vinculado desde esas páginas.
No desea que sus páginas de contenido detallado se salgan del índice debido al manejo deficiente de la paginación.
Cada página dentro de una serie paginada debe tener un canónico autorreferencial, a menos que use una página Ver todo.
Use el rel = canonical incorrectamente y es probable que Googlebot simplemente ignore su señal.
Páginas paginadas de Noindex

Un método clásico para resolver problemas de paginación fue una etiqueta noindex de robots para evitar que los motores de búsqueda indexen el contenido paginado.
Confiar únicamente en la etiqueta noindex para el manejo de la paginación dará como resultado que no se tengan en cuenta las señales de clasificación de las páginas de componentes.
Sin embargo, el problema más grande con este método es que un noindex a largo plazo en una página eventualmente llevará a Google a no seguir los enlaces en esa página.
Esto podría hacer que el contenido vinculado desde las páginas paginadas se elimine del índice.
Paginación y desplazamiento infinito o cargar más o scroll infinito

Una forma más nueva de manejo de paginación es:
Desplazamiento infinito, donde el contenido se obtiene previamente y se agrega directamente a la página actual del usuario a medida que se desplaza hacia abajo.
Cargue más, donde el contenido se procesa al hacer clic en el botón «ver más». Los usuarios aprecian estos enfoques, pero ¿Googlebot? No tanto.
Googlebot no emula comportamientos como desplazarse al final de una página o hacer clic para cargar más.
Es decir, sin ayuda, los motores de búsqueda no pueden rastrear de manera efectiva todo su contenido.
Para ser compatible con SEO, convierta su desplazamiento infinito en una serie paginada equivalente, basada en enlaces de anclaje rastreables con atributos href, que sea accesible incluso con JavaScript deshabilitado.
A medida que el usuario se desplaza o hace clic, use JavaScript para adaptar la URL en la barra de direcciones a la página paginada de componentes.
Además, implemente un pushState para cualquier acción del usuario que se parezca a un clic o que pase activamente una página. Puede consultar esta funcionalidad en la demostración creada por John Mueller:
https://scrollsample.appspot.com/items
Esencialmente, todavía está implementando las mejores prácticas de SEO recomendadas anteriormente, solo está agregando funcionalidad adicional de experiencia de usuario en la parte superior.
Desalentar o bloquear Paginación arrastrándose

Algunos profesionales de SEO recomiendan evitar el problema del manejo de la paginación por completo simplemente bloqueando a Google para que no rastree URL paginadas.
En tal caso, desearía tener mapas de sitio XML bien optimizados para garantizar que las páginas vinculadas mediante paginación tengan la posibilidad de ser indexadas.
Hay tres formas de bloquear los rastreadores:
- La forma desordenada: agregue nofollow a todos los enlaces que apuntan a páginas paginadas.
- La forma más limpia: usar un archivo robots.txt disallow.
- La forma no necesaria para el desarrollador: establezca el parámetro de página paginada en «Paginates» y que Google rastree «Sin URL» en Google Search Console.
Al utilizar uno de estos métodos para disuadir a los motores de búsqueda de rastrear URL paginadas, usted:
- Evita que los motores de búsqueda reconozcan las señales de clasificación de las páginas paginadas.
- Evita el paso de la equidad de enlaces internos de páginas paginadas a las páginas de contenido de destino.
- Impedir la capacidad de Google para descubrir sus páginas de contenido de destino.
La ventaja obvia es que ahorras en el presupuesto de rastreo. No hay una versión idónea. Debe decidir cuál es la prioridad para su sitio web.
Personalmente, si tuviera que priorizar el presupuesto de rastreo, lo haría utilizando el manejo de paginación en Google Search Console, ya que tiene la flexibilidad óptima para cambiar de opinión.
Seguimiento del impacto KPI de la paginación
Entonces, ahora sabe qué hacer, ¿cómo rastrea el efecto del manejo de optimización de paginación?
En primer lugar, recopile datos de referencia para comprender cómo su entrega actual de paginación está impactando el SEO.
Las fuentes de KPI pueden incluir:
Archivos de registro del servidor para la cantidad de rastreos de página paginados.
Sitio: operador de búsqueda (por ejemplo, sitio: ejemplo.com inurl: página) para comprender cuántas páginas paginadas ha indexado Google.
Informe de Google Search Console, Search Analytics filtrado por páginas que contienen paginación para comprender la cantidad de impresiones.
Informe de la página de destino de Google Analytics filtrado por URL paginadas para comprender el comportamiento en el sitio.
Si ve un problema para que los motores de búsqueda rastreen la paginación de su sitio para llegar a su contenido, es posible que desee cambiar los enlaces de paginación.
Una vez que haya lanzado su gestión de paginación de mejores prácticas, vuelva a visitar estas fuentes de datos para medir el éxito de sus esfuerzos.
Conclusion sobre buenas prácticas de páginaciones
Básicamente la correcta paginación seo consistirá en evitar contendio duplicado e indexar todos los contendiso que se enceuntren en nuestro páginado siempre que estos los queramos indexar.
En el caso de que se así deberemos imple,mentar las directrices rel=next y rel=prev ademas de introducir el auto referenciado.
Por otra parte si queremos implementar la funcionalidad de páginación conScroll (la mejor en mi opinión deberemos seguir el ejemplo desarrollado por John Mueller
https://scrollsample.appspot.com/items
Recursos en Español en Referencia a las paginaciones
- https://moz.com/blog/seo-guide-to-google-webmaster-recommendations-for-pagination
- https://www.searchenginejournal.com/technical-seo/pagination/
- https://www.deepcrawl.com/knowledge/technical-seo-library/pagination-seo-guide/
