
¿Qué es un archivo robots.txt? Robots.txt es un archivo de texto que los webmasters crean para instruir a los robots web (generalmente robots de motores de búsqueda) sobre cómo rastrear páginas en su sitio web.
¿En que consiste el Robots.txt?
El archivo robots.txt es parte del protocolo de exclusión de robots (REP), un grupo de estándares web que regulan cómo los robots rastrean la web, acceden e indexan contenido y sirven ese contenido a los usuarios.
El REP también incluye directivas como meta robots, así como instrucciones de página, subdirectorio o en todo el sitio sobre cómo los motores de búsqueda deben tratar los enlaces (como «seguir» o «no seguir»).
En la práctica, los archivos robots.txt indican si ciertos agentes de usuario (software de rastreo web) pueden o no rastrear partes de un sitio web.
Estas instrucciones de rastreo se especifican al «dissallow» o «allow» el comportamiento de ciertos (o todos) agentes de usuario.
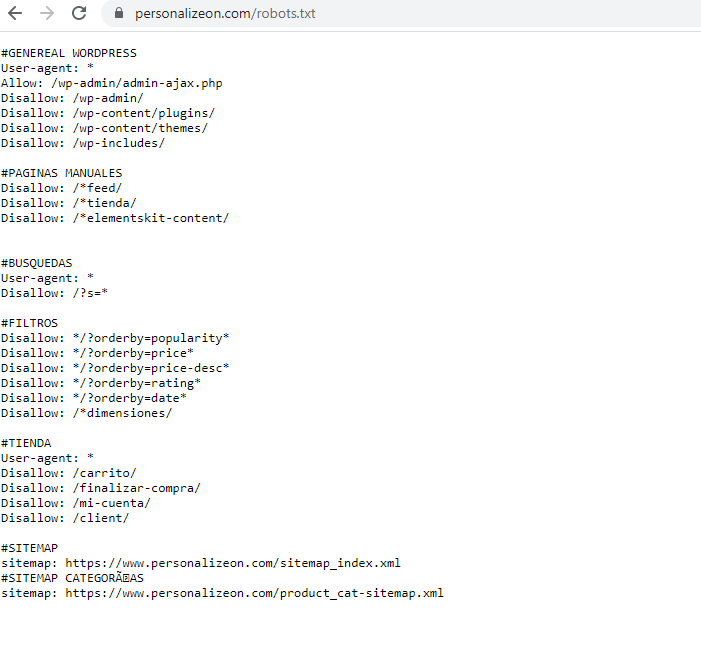
Formato básico sobre el Robot.txt
Agente de usuario:
- [nombre del agente de usuario] Dissallow: [la cadena de URL no se debe rastrear]
Juntas, estas dos líneas se consideran un archivo robots.txt completo, aunque un archivo de robots puede contener varias líneas de agentes de usuario y directivas (es decir, no permite, permite, demora el rastreo, etc.).
Dentro de un archivo robots.txt, cada conjunto de directivas de usuario-agente aparece como un conjunto discreto, separado por un salto de línea:
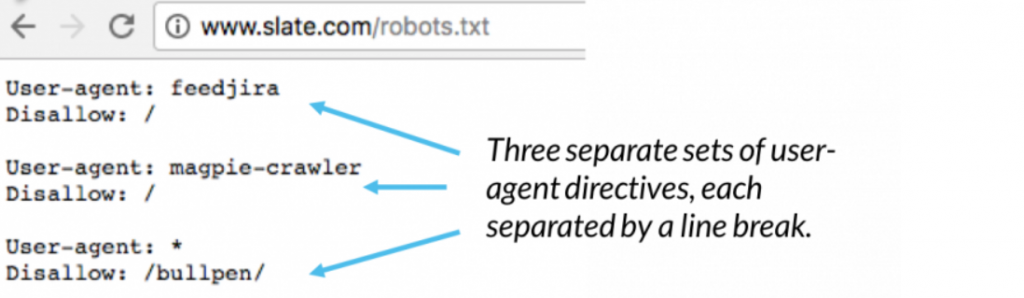
En un archivo robots.txt con varias directivas de agente de usuario, cada regla de Dissallow o Allow solo se aplica a los agentes de uso especificados en ese conjunto separado de salto de línea en particular.
Si el archivo contiene una regla que se aplica a más de un agente de usuario, un rastreador solo prestará atención (y seguirá las instrucciones) al grupo de instrucciones más específico.
Aquí hay un ejemplo:

Msnbot, discobot y Slurp se mencionan específicamente, por lo que esos agentes de usuario solo prestarán atención a las directivas en sus secciones del archivo robots.txt. Todos los demás agentes de usuario seguirán las directivas en el grupo de agente de usuario: *.
Ejemplo de robots.txt:
Aquí hay algunos ejemplos de robots.txt en acción para un sitio www.example.com:
URL del archivo Robots.txt: www.example.com/robots.txt
Bloquear todos los rastreadores web de todo el contenido
Usuario-agente: * Disallow: /
El uso de esta sintaxis en un archivo robots.txt indicaría a todos los rastreadores web que no rastreen ninguna página en www.example.com, incluida la página de inicio.
Permitir a todos los rastreadores web acceder a todo el contenido
Usuario-agente: * Disallow:
El uso de esta sintaxis en un archivo robots.txt le dice a los rastreadores web que rastreen todas las páginas en www.example.com, incluida la página de inicio.
Bloquear un rastreador web específico desde una carpeta específica
User-agent: Googlebot Disallow: / example-subfolder /
Esta sintaxis solo le dice al rastreador de Google (nombre de agente de usuario Googlebot) que no rastree ninguna página que contenga la cadena URL www.example.com/example-subfol … un rastreador web específico de una página web específica
Agente de usuario: BingbotDisallow: /example-subfolder/blocked-page.html
Esta sintaxis solo le dice al rastreador de Bing (nombre de agente de usuario Bing) que evite rastrear la página específica en www.example.com/example-subfol … ¿funciona robots.txt?
Los motores de búsqueda tienen 2 trabajos principales:
Rastreando la web para descubrir contenido.
Indexación de ese contenido para que pueda ser entregado a los buscadores que buscan información.
Para rastrear sitios, los motores de búsqueda siguen enlaces para ir de un sitio a otro y, en última instancia, rastrean miles de millones de enlaces y sitios web. Este comportamiento de rastreo a veces se conoce como «araña».
Después de llegar a un sitio web pero antes de explorarlo, el rastreador de búsqueda buscará un archivo robots.txt.
Cuando el Bot encuentra uno, el rastreador cómo consecuencia se dedicará su recursos a revisar ese archivo primero antes de continuar por la página.
Debido a que el archivo robots.txt contiene información sobre cómo debe rastrearse el motor de búsqueda, la información que se encuentra allí le indicará una acción adicional del rastreador en este sitio en particular. Si el archivo robots.txt no contiene ninguna directiva que no permita la actividad de un agente de usuario (o si el sitio no tiene un archivo robots.txt), procederá a rastrear otra información en el sitio.
Otros robots rápidos que debe saber:
Para poder encontrarlo, se debe colocar un archivo robots.txt en el directorio de nivel superior de un sitio web.
Robots.txt distingue entre mayúsculas y minúsculas: el archivo debe denominarse «robots.txt» (no Robots.txt, robots.TXT u otro).
Algunos agentes de usuario (robots) pueden optar por ignorar su archivo robots.txt. Esto es especialmente común con rastreadores más nefastos como robots de malware o raspadores de direcciones de correo electrónico.
El archivo /robots.txt está disponible públicamente: simplemente agregue /robots.txt al final de cualquier dominio raíz para ver las directivas de ese sitio web (¡si ese sitio tiene un archivo robots.txt!). Esto significa que cualquiera puede ver qué páginas hace o no desea que se rastreen, así que no las use para ocultar información privada del usuario.
Cada subdominio en un dominio raíz usa archivos robots.txt separados. Esto significa que tanto blog.example.com como example.com deben tener sus propios archivos robots.txt (en blog.example.com/robots.txt y example.com/robots.txt).
En general, es una buena práctica indicar la ubicación de los mapas de sitio asociados con este doma
en la parte inferior del archivo robots.txt. Aquí hay un ejemplo:
Sitemaps en robots.txt
Sintaxis técnica de robots.txt
La sintaxis de Robots.txt puede considerarse como el «idioma» de los archivos robots.txt. Hay cinco términos comunes que probablemente encuentres en un archivo de robots. Incluyen:
Agente de usuario: el rastreador web específico al que le está dando instrucciones de rastreo (generalmente un motor de búsqueda). Puede encontrar una lista de la mayoría de los agentes de usuario aquí.
Disallow: el comando utilizado para indicarle a un agente de usuario que no rastree URL en particular. Solo se permite una línea «Disallow:» para cada URL.
Permitir (solo aplicable para el robot de Google): el comando para indicarle al robot de Google que puede acceder a una página o subcarpeta aunque su página principal o subcarpeta no esté permitida.
Rastreo-retraso: cuántos segundos debe esperar un rastreador antes de cargar y rastrear el contenido de la página. Tenga en cuenta que Googlebot no reconoce este comando, pero la frecuencia de rastreo se puede establecer en Google Search Console.
Mapa del sitio: se utiliza para indicar la ubicación de cualquier mapa del sitio XML asociado con esta URL. Tenga en cuenta que este comando solo es compatible con Google, Ask, Bing y Yahoo.
La coincidencia de patrones
Cuando se trata de bloquear o permitir las URL reales, los archivos robots.txt pueden volverse bastante complejos ya que permiten el uso de la coincidencia de patrones para cubrir un rango de posibles opciones de URL. Google y Bing honran dos expresiones regulares que pueden usarse para identificar páginas o subcarpetas que un SEO quiere excluir. Estos dos caracteres son el asterisco (*) y el signo de dólar ($).
- es un comodín que representa cualquier secuencia de caracteres
$ coincide con el final de la URL
Google ofrece una gran lista de posibles sintaxis de coincidencia de patrones y ejemplos aquí.
¿A dónde va el archivo robots.txt en un sitio?
Cada vez que visitan un sitio, los motores de búsqueda y otros robots de rastreo web (como el rastreador de Facebook, Facebot) saben que deben buscar un archivo robots.txt. Pero solo buscarán ese archivo en un lugar específico: el directorio principal (generalmente su dominio raíz o página de inicio).
Si un agente de usuario visita www.example.com/robots.txt y no encuentra un archivo de robots allí, asumirá que el sitio no tiene uno y procederá a rastrear todo en la página (y tal vez incluso en todo el sitio).
Incluso si la página de robots.txt existiera en, por ejemplo, ejemplo.com/index/robots.txt o www.example.com/homepage/robots.txt, los agentes de usuario no la descubrirían y, por lo tanto, el sitio sería tratado como si no tuviera ningún archivo de robots.
Para asegurarse de encontrar su archivo robots.txt, inclúyalo siempre en su directorio principal o dominio raíz.
¿Por qué necesitas robots.txt?
Los archivos Robots.txt controlan el acceso del rastreador a ciertas áreas de su sitio. Si bien esto puede ser muy peligroso si accidentalmente no permite que Googlebot rastree todo su sitio (!!), hay algunas situaciones en las que un archivo robots.txt puede ser muy útil.
Algunos casos de uso comunes incluyen:
Evitar que el contenido duplicado aparezca en SERPs (tenga en cuenta que los meta robots suelen ser una mejor opción para esto)
Mantener privadas secciones enteras de un sitio web (por ejemplo, el sitio de preparación de su equipo de ingeniería)
Evitar que las páginas de resultados de búsqueda interna aparezcan en un SERP público
Especificar la ubicación de los mapas del sitio
Evitar que los motores de búsqueda indexen ciertos archivos en su sitio web (imágenes, PDF, etc.)
Especificar un retraso de rastreo para evitar que sus servidores se sobrecarguen cuando los rastreadores cargan múltiples piezas de contenido a la vez
Si no hay áreas en su sitio en las que desee controlar el acceso de agente de usuario, es posible que no necesite un archivo robots.txt.
Comprobando si tiene un archivo robots.txt
¿No está seguro si tiene un archivo robots.txt? Simplemente escriba su dominio raíz, luego agregue /robots.txt al final de la URL. Por ejemplo, el archivo de robots de Moz se encuentra en moz.com/robots.txt.
Si no aparece una página .txt, actualmente no tiene una página (en vivo) robots.txt.
Cómo crear un archivo robots.txt
Si descubrió que no tenía un archivo robots.txt o desea modificar el suyo, crear uno es un proceso simple.
Este artículo de Google explica el proceso de creación del archivo robots.txt, y esta herramienta le permite probar si su archivo está configurado correctamente.
¿Busca práctica para crear archivos de robots? Esta publicación de blog muestra algunos ejemplos interactivos.
Mejores prácticas de SEO sobre Robots.txt
Asegúrese de no bloquear el contenido o las secciones de su sitio web que desea rastrear.No se seguirán los enlaces en páginas bloqueadas por robots.txt. Esto significa 1.)
A menos que también estén vinculados desde otras páginas accesibles para motores de búsqueda (es decir, páginas no bloqueadas a través de robots.txt, meta robots u otros), los recursos vinculados no se rastrearán ni podrán indexarse.
2.) No se puede transferir la equidad del enlace desde la página bloqueada al destino del enlace. Si tiene páginas a las que desea que se transfiera el capital, use un mecanismo de bloqueo diferente que no sea robots.txt.
No utilice el archivo robots.txt para evitar que los datos confidenciales (como la información privada del usuario) aparezcan en los resultados de SERP. Debido a que otras páginas pueden enlazar directamente a la página que contiene información privada (evitando así las directivas de robots.txt en su ro
ot dominio o página de inicio), aún puede indexarse. Si desea bloquear su página de los resultados de búsqueda, use un método diferente como la protección con contraseña o la meta directiva noindex.
Algunos motores de búsqueda tienen múltiples agentes de usuario. Por ejemplo, Google usa Googlebot para búsqueda orgánica y Googlebot-Image para búsqueda de imágenes. La mayoría de los agentes de usuario del mismo motor de búsqueda siguen las mismas reglas, por lo que no es necesario especificar directivas para cada uno de los múltiples rastreadores de un motor de búsqueda, pero tener la capacidad de hacerlo le permite ajustar cómo se rastrea el contenido de su sitio.
Un motor de búsqueda almacenará en caché el contenido de robots.txt, pero generalmente actualiza el contenido en caché al menos una vez al día. Si cambia el archivo y desea actualizarlo más rápido de lo que está ocurriendo, puede enviar su URL de robots.txt a Google.
Robots.txt vs meta robots vs x-robots
¡Tantos robots! ¿Cuál es la diferencia entre estos tres tipos de instrucciones de robot? En primer lugar, robots.txt es un archivo de texto real, mientras que los meta y x-robots son meta directivas.
Más allá de lo que realmente son, los tres cumplen diferentes funciones. Robots.txt dicta el comportamiento de rastreo del sitio o del directorio, mientras que los robots meta y x pueden dictar el comportamiento de indexación a nivel de página individual (o elemento de página)
Artículos relacionados:
Preguntas relacionadas con el robots.txt:
Para saber si una página tiene un archivo robot.txt, puedes seguir estos pasos:
1. Abre tu navegador web y visita la página web que deseas comprobar.
2. Agrega «/robots.txt» al final de la URL del sitio web. Por ejemplo, si la URL del sitio web es «https://www.ejemplo.com«, deberás escribir «https://www.ejemplo.com/robots.txt
Si la página tiene un archivo robot.txt, deberías ver el contenido del archivo en tu navegador.
Si la página no tiene un archivo robot.txt, es posible que veas un mensaje de error como «404 Not Found».
También puedes utilizar herramientas en línea para comprobar si un sitio web tiene un archivo robot.txt, como por ejemplo el «Probador de robots.txt» de Google, que te permite comprobar la presencia y contenido de este archivo en un sitio web.
«Disallow» en el archivo robots.txt es una directiva que se utiliza para indicar a los robots de los motores de búsqueda que no rastreen o indexen una determinada página web, directorio o archivo en el sitio.
Cuando se especifica una URL con la directiva «Disallow», se le dice al robot que no acceda a esa URL específica o a cualquier subdirectorio o archivo que se encuentre debajo de ella.
Por ejemplo, si en el archivo robots.txt se encuentra la directiva «Disallow: /carpeta/», se le está indicando al robot que no rastree ninguna página o archivo que se encuentre en la carpeta especificada.
Del mismo modo, si se utiliza la directiva «Disallow: /archivo.html», se le está diciendo al robot que no indexe la página web especificada.
Es importante tener en cuenta que, aunque los robots de los motores de búsqueda respetan estas directivas, no son obligatorias y algunos robots pueden ignorarlas. Por lo tanto, «Disallow» no es una garantía absoluta de que una página o archivo no será rastreado o indexado por los motores de búsqueda.
